

Databases & Analytics
Types of Databases
Relational vs Non-Relational
Key differences are how data are managed and how data are stored
| Relational | Non-Relational |
|---|---|
| Organized by tables, rows, and columns | Varied data storage models |
| Rigid schema (Structured Query Language / SQL) | Flexible schema (NoSQL) - data stored in key-value pairs, columns, documents, or graphs |
| Rules enforced within the database | Rules can be defined in application code (outside the database) |
| Typically scaled vertically - This is where, for instance, we would deploy a database on an instance and then change the instance type to one with more CPU and memory if we need to scale the database | Scales horizontally |
| Supports complex queries and joins | Unstructured, simple language that supports any kind of schema |
| Amazon RDS, Oracle, MySQL, IBM DB2, PostgreSQL | Amazon DynamoDB, MongoDB, Redis, Neo4j |
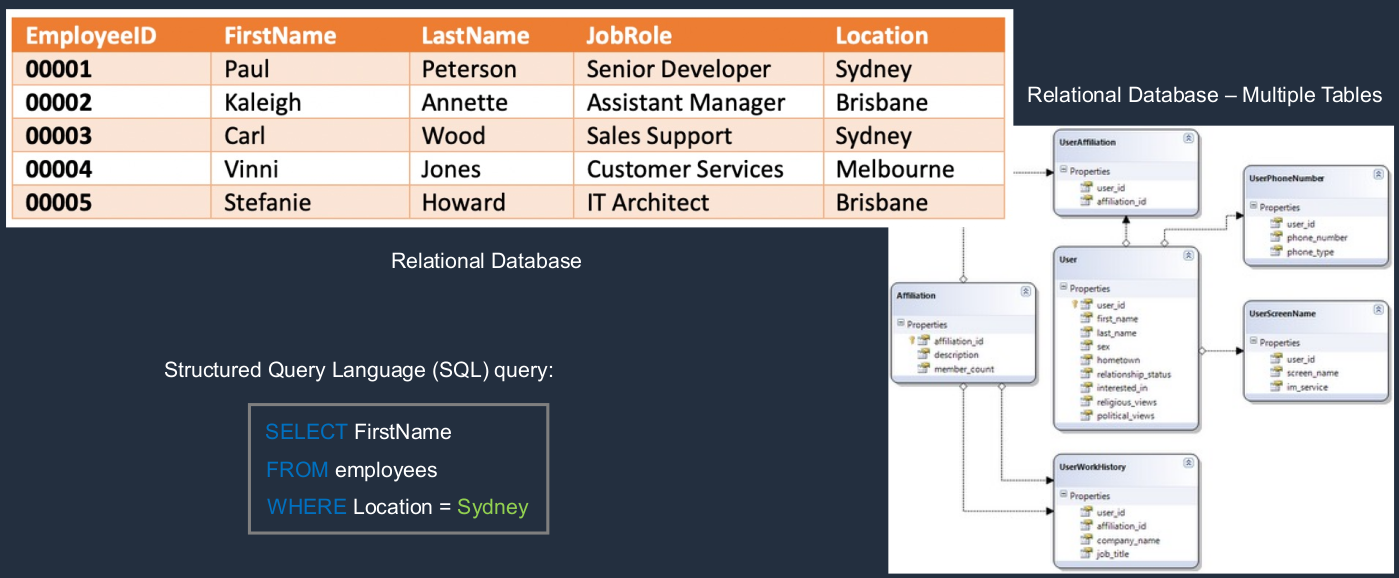
Relational Databases
Here we have an example of a table in a relational database. As you see, we have columns and we have rows and each row is an individual item in the database. Now, if we have multiple tables, we can connect them, that’s how we can join different tables together. If we want to query the database, that’s when we use the Structured Query Language (SQL). So here, we might select by the first name from employees and where we want the location to equal Sydney. So it’s going to pull out resources based on these definitions in the SQL query.
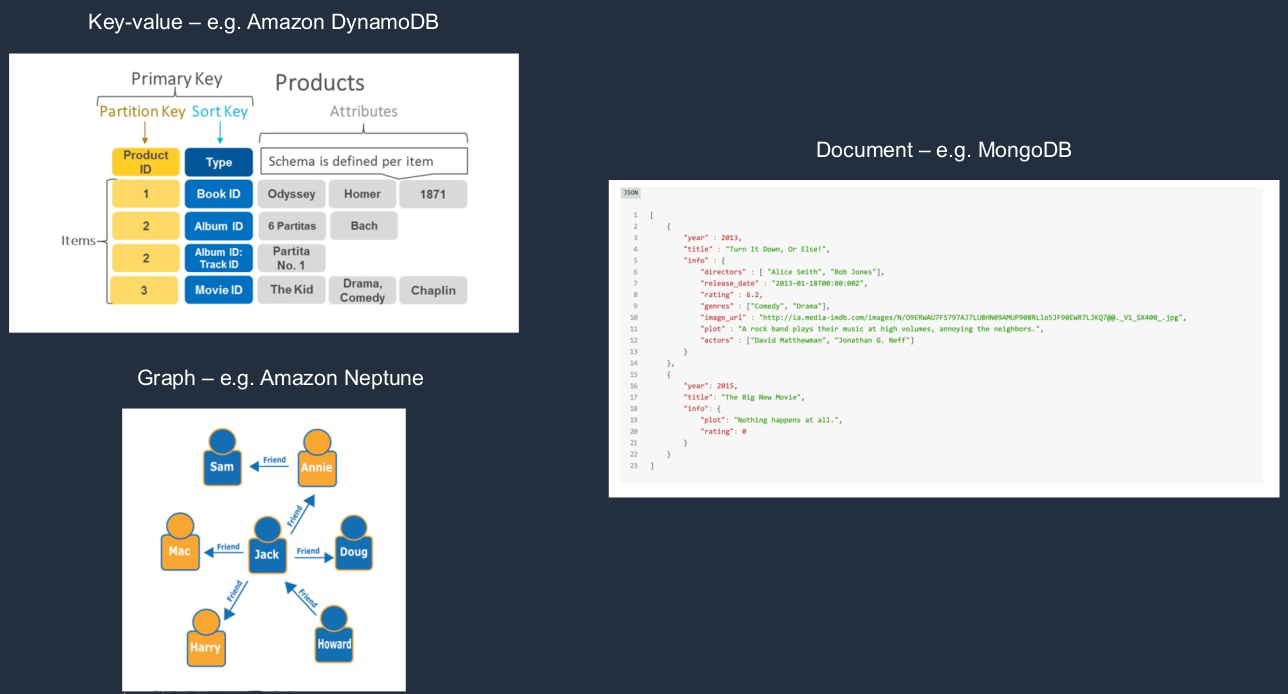
Types of Non-Relational DB (NoSQL)
So here, for example, we have DynamoDB. DynamoDB has items in a table and those items have attributes and the attributes can be different for every item. They don’t have to be the same and some can be missing. So it’s much more flexible in that regard. We’ve got MongoDB, which is a document type of database. So you’re storing documents as items in the database and then we have graph databases like Amazon Neptune. These are all non-relational. A graph database is something like, you can think of Facebook and the way you store relationships between different people on Facebook. You’re storing those relationships in a graph database.
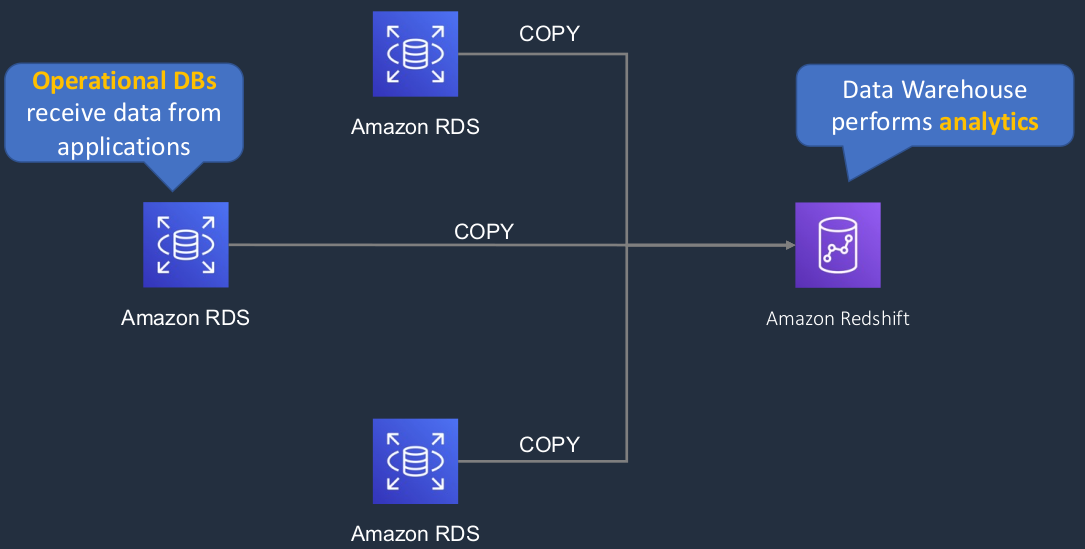
Operational vs Analytical
Key differences are use cases and how the database is optimized
| Operational / Transactional | Analytical |
|---|---|
| Online Transaction Processing (OLTP) - Think of these as the production databases. So maybe you’re an eCommerce platform and your orders are going into this database. That would be your operational database. | Online Analytics Processing (OLAP) - the source data comes from OLTP DBs - Now with Analytical databases, the data is coming from your operational databases, so you’re loading that data into your analytical database. It then becomes what’s known as a data warehouse and it’s often separated from your front-facing databases, those operational databases. |
| Production DBs that process transactions. E.g. adding customer records, checking stock availability (INSERT, UPDATE, DELETE) | Data warehouse. Typically, separated from the customer-facing DBs. Data is extracted for decision making |
| Short transactions and simple queries | Long transactions and complex queries |
| Relational examples: Amazon RDS, Oracle, IBM DB2 | Relational examples: Amazon RedShift, Teradata, HPVertica |
| Non-relational examples: MongoDB, Cassandra, Neo4j, HBase | Non-relational examples: Amazon EMR, MapReduce |
We have several Amazon RDS databases, maybe these are in different parts of the world and those are our operational databases and then we have RedShift, which is a data warehouse for analytics. So we’re able to copy and load that data into RedShift and then perform our analytics on that data and we’ve aggregated it from all of the different operational databases we have.
AWS Databases
| Data Store | Use Case |
|---|---|
| Database on EC2 | * Need full control over instance and database
* Third-party database engine (not available in RDS) |
| Amazon RDS | * Need traditional relational database
* e.g. Oracle, PostgreSQL, Microsoft SQL, MariaDB, MySQL * Data is well-formed and structured |
| Amazon DynamoDB | * NoSQL database
* In-memory performance
* High I/O needs * Dynamic scaling |
| Amazon Redshift | * Data warehouse for large volumes of aggregated data |
| Amazon ElasticCache | * Fast temporary storage for small amounts of data * In-memory database |
| Amazon EMR | * Analytics workloads using the Hadoop framework |
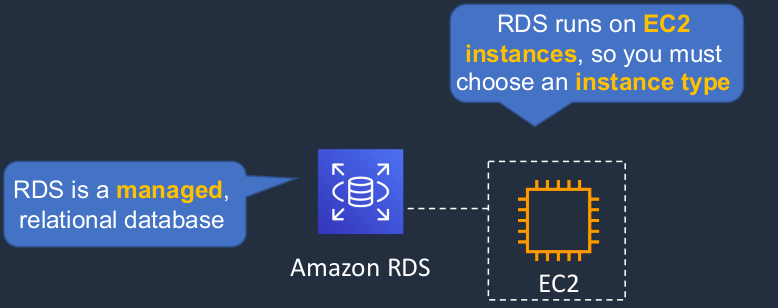
Amazon Relational Database Service (RDS)
RDS is a managed relational database. Now it runs on EC2 instances, and that means you need to choose your instance type to determine the performance characteristics for your database, the CPU, the memory, the storage, and so on.
RDS supports the following database engines:
- Amazon Aurora: proprietary AWS database
- MySQL
- MariaDB
- Oracle
- Microsoft SQL Server
- PostgreSQL
Now, if the database you need is not on the list, you can’t use RDS. You have to install it on EC2.
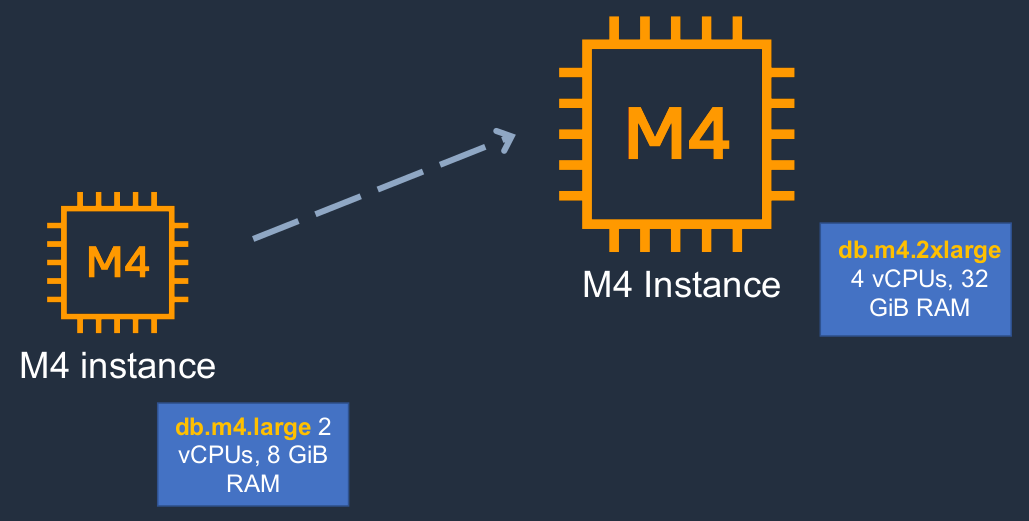
Amazon RDS Scaling Up (vertically)
So scaling up, scaling vertically is where we change our instance type. So here we’ve moved from db.m4.large with two CPUs and 8GiB RAM up to the M4 which has more processing power and more RAM associated with it.
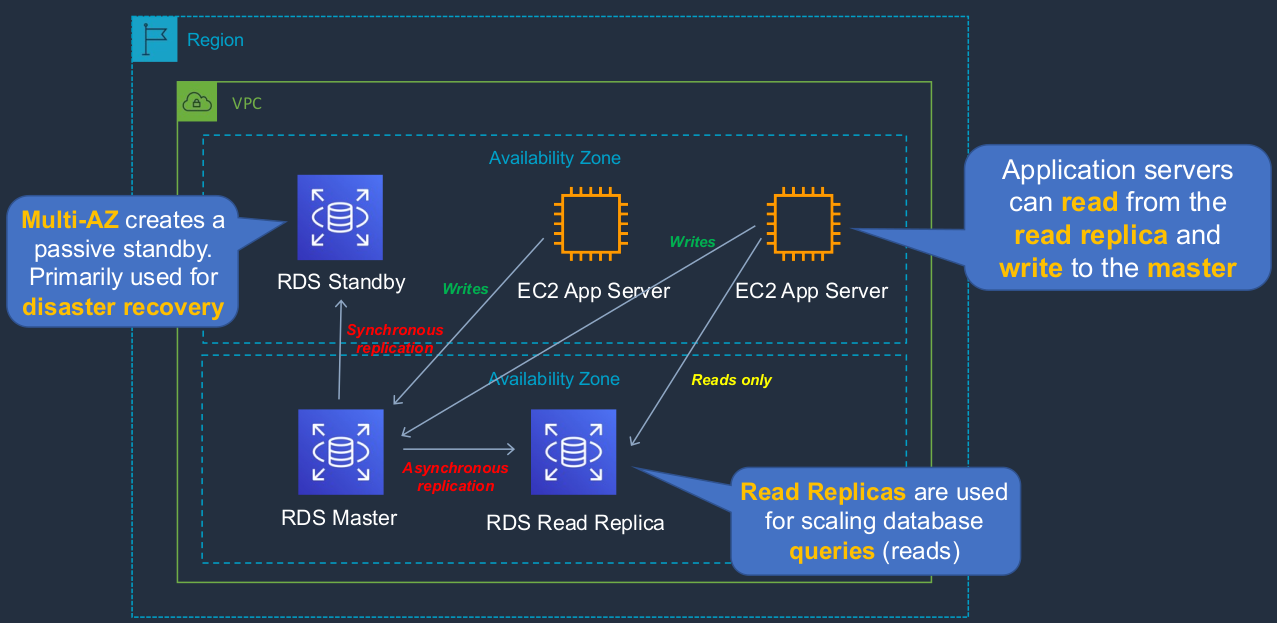
Disaster Recovery (DR) and Scaling Out (Horizontally)
Now we can also scale out for some specific performance characteristics and we can also implement disaster recovery so we can have some high availability fault tolerance and disaster recovery for our applications. So how does that work? We have something called an RDS master. So this is running in an availability zone and this is our primary database. It’s the one on which both reads and writes get performed. We can then have a standby instance. Now the master will synchronously replicate to the standby instance. So the standby is always in sync with the master. Now, this is known as multi-az and you essentially have a passive standby that is used for disaster recovery. So that means in a dire situation, when the master fails or becomes inaccessible, then the standby can take over it automatically. We also have a Read Replica. Now, Read Replicas use asynchronous replication, so there’s a little bit more of a delay but they replicate from the master as well and they’re used for scaling reads. That means scaling the queries on your database. So this is a way of scaling out, scaling horizontally, but only for queries. The Read Replica is used for queries, the writes still always go to the master database. So here we have our app server and we can see in green all writes are going to the master, but Reads can instead go to the Read Replica so that we can scale and offload a bit of the performance impact from the master to the replica.
Amazon RDS
- RDS uses EC2 instances, so you must choose an instance family/type
- Relational databases are known as Structured Query Language (SQL) databases
- RDS is an Online Transaction Processing (OLTP) type of database
- Easy to set up, highly available, fault-tolerant, and scalable
- Common use cases include online stores and banking systems
- You can encrypt your Amazon RDS instances and snapshots at rest by enabling the encryption option for your Amazon RDS DB instance (during creation)
- Encryption uses AWS Key Management Service (KMS)
- Amazon RDS supports the following database engines:
- SQL Server
- Oracle
- MySQL Server
- PostgreSQL
- Aurora
- MariaDB
- Scales up by increasing instance size (compute and storage)
- Read replicas option for read-heavy workloads (scales out for reads/ queries only)
- Disaster recovery with Multi-AZ option
Create Amazon RDS Database
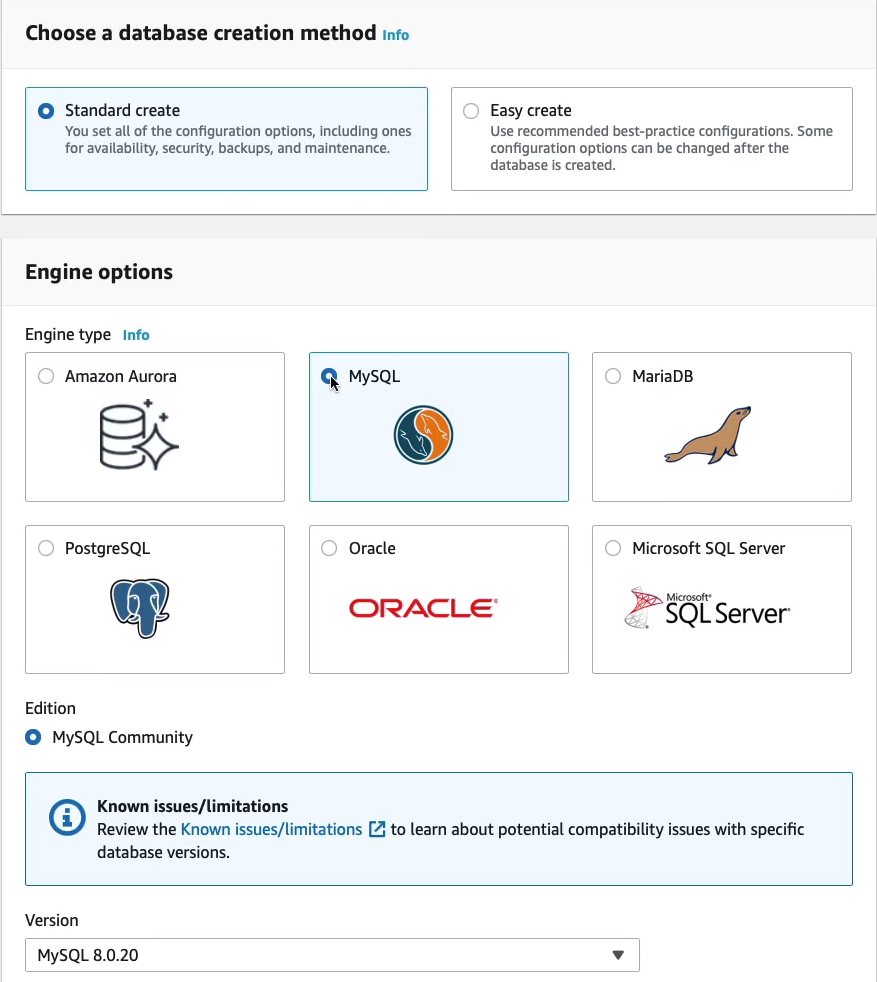
Let’s head over to the Management Console > Services > Database > RDS. Now, on the main screen here, if we go to Dashboard, we’ve got Amazon Aurora. AWS wants us to choose Amazon Aurora, that’s their own database engine for RDS. Now we can click on Create database here. We don’t have to use Aurora.

So for now, rather than choosing the Engine as Aurora, I’m going to choose MySQL instead and you can see we have a choice of other database engines if we want to. So I’m running MySQL.
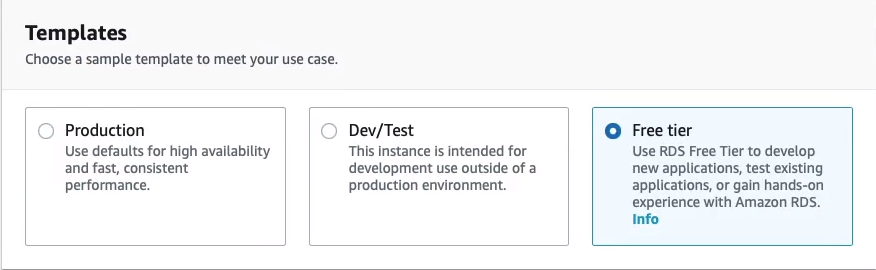
Let’s scroll down. Here we’ve got some Templates. So what we’re going to do is use the Free tier and the Free tier will then configure this environment to make sure we stay within the free tier. Now there are some limitations. For example, you won’t be able to enable multi-AZ, but that’s fine for this. Otherwise, you could use the presets for production r dev/test workloads.
We need to provide a database identifier. I’m just going to call min digitalcloud. The Master username is here, the admin’s fine, and I’m just going to put in a password.
Next, we can choose the Database instance class. Now, because we’ve already selected the free tier, most of them are going to be grayed out and if we deselect that and change to Production, then we’d be able to choose from some of these larger database instance types. So I’m happy with the db.t2.micro.
Scrolling down a bit, we have Storage and it’s using EBS (Elastic Block Store) because this is running on EC2. So we can choose from General purpose, Provisioned IOPS, or Magnetic. I’m going to leave it on General-Purpose (SSD) and 20 GiB is fine and it enables storage auto-scaling by default. So this means that the storage layer will automatically scale for us as we use more storage.
As you can see, Multi-AZ is grayed out that’s because we’re on the free tier.
Note here that you can enable Public access. So if you do that, it means that you could have application instances coming in from the outside world to a public address and connected to your database. You might want it to be completely internal, so just leave it on No. You can choose a VPC security group also if you want to. In this case, it chooses the default and that’s fine for this purpose.
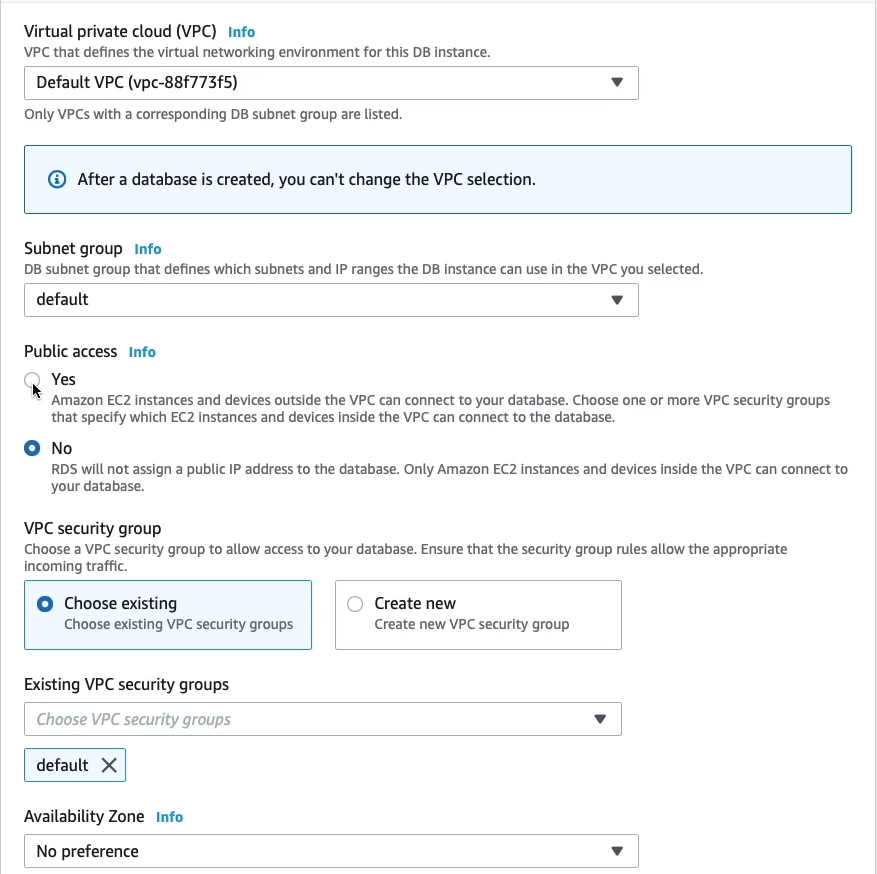
Let’s just check the Additional configuration. I want the Initial database name to be digitalcloud and I’m going to leave the automatic backups on. As you can see, you can also define your retention period. By default, it’s 7 days. You can knock it down to zero, which means no backups, or put it up to 35. We’ll leave it as it is. And I’m happy with not having a preference for the backup window. That’s the time when AWS will take the backup. You can choose your own time frame to make sure it doesn’t interfere with your production systems if you want to.
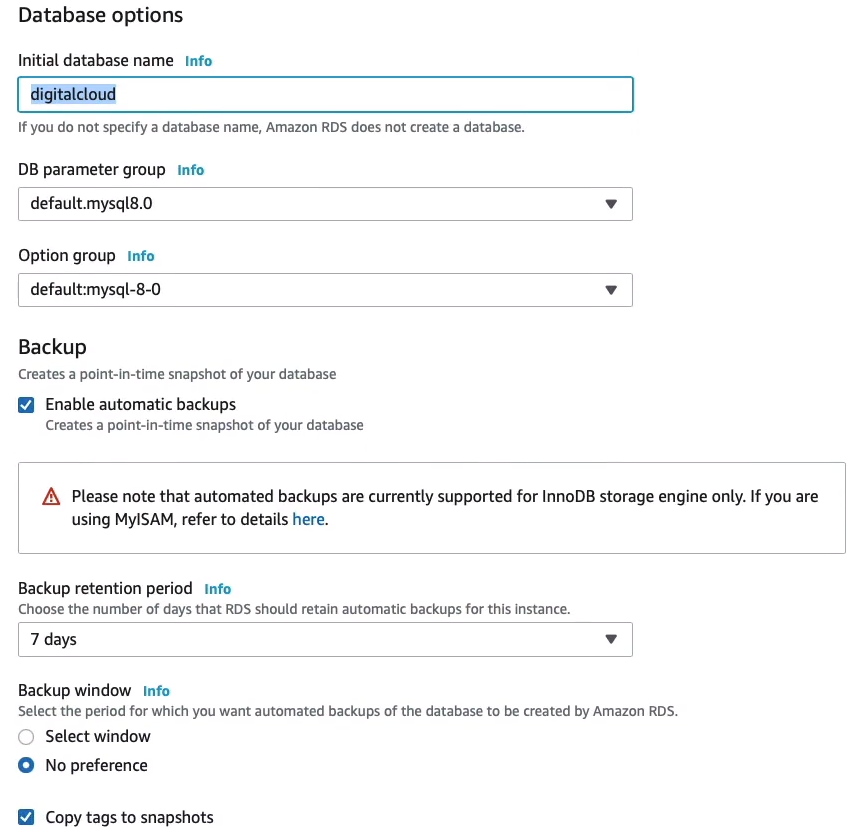
Let’s just scroll down and Create database.
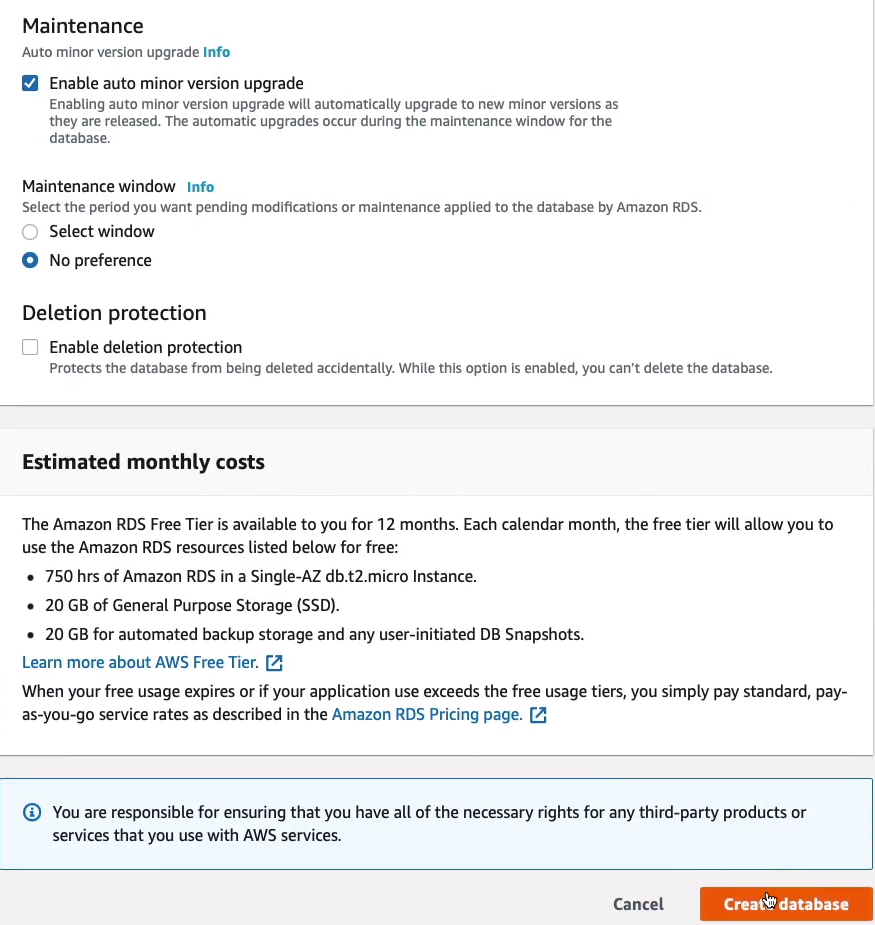
Our database is now in the creating status and it can take several minutes for an RDS database to deploy. Once it’s deployed we’ll see that we have an endpoint and that’s the endpoint we can then use for our applications. So let’s just give it a few minutes to deploy.
So my database is almost deployed. We can see it’s in backing up status now and if I just click on the database here.
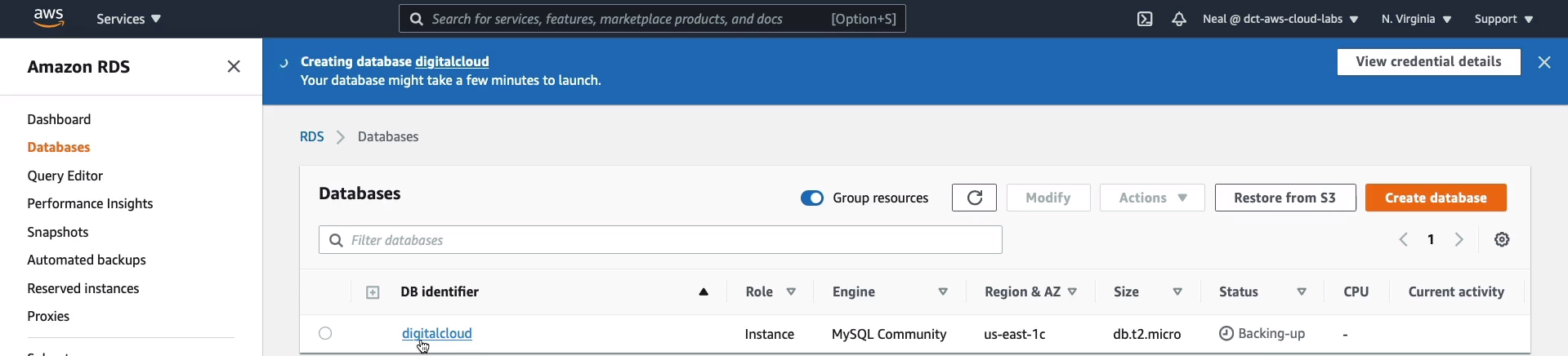
We can now see that we have an Endpoint & port. This endpoint would be used in your application to point it to the RDS database and the port would be 3306. Now you can see a bit of information about the availability zone it’s in, the VPC, the subnet group, and so on. Now, make sure that if you are using this to point an application, you go and check your VPC security group because your application will need to be allowed to talk to RDS on port 3306.
At the moment, if we scroll down we can see that we don’t have a rule there. So actually, the default security group only has an inbound rule allowing access from itself. So, your application, if it was in this particular security group, that would work otherwise you would need to allow 3306 inbound from another security group or IP address.

We then have the Monitoring tab and here we can see a little bit of information about CPU, database connections, storage space, freeable memory, and then read and write IOPS.
We’ve got Logs & events and you can see some information is being populated in here.
Under Configuration, you can see a few more details on the configuration of this RDS instance.
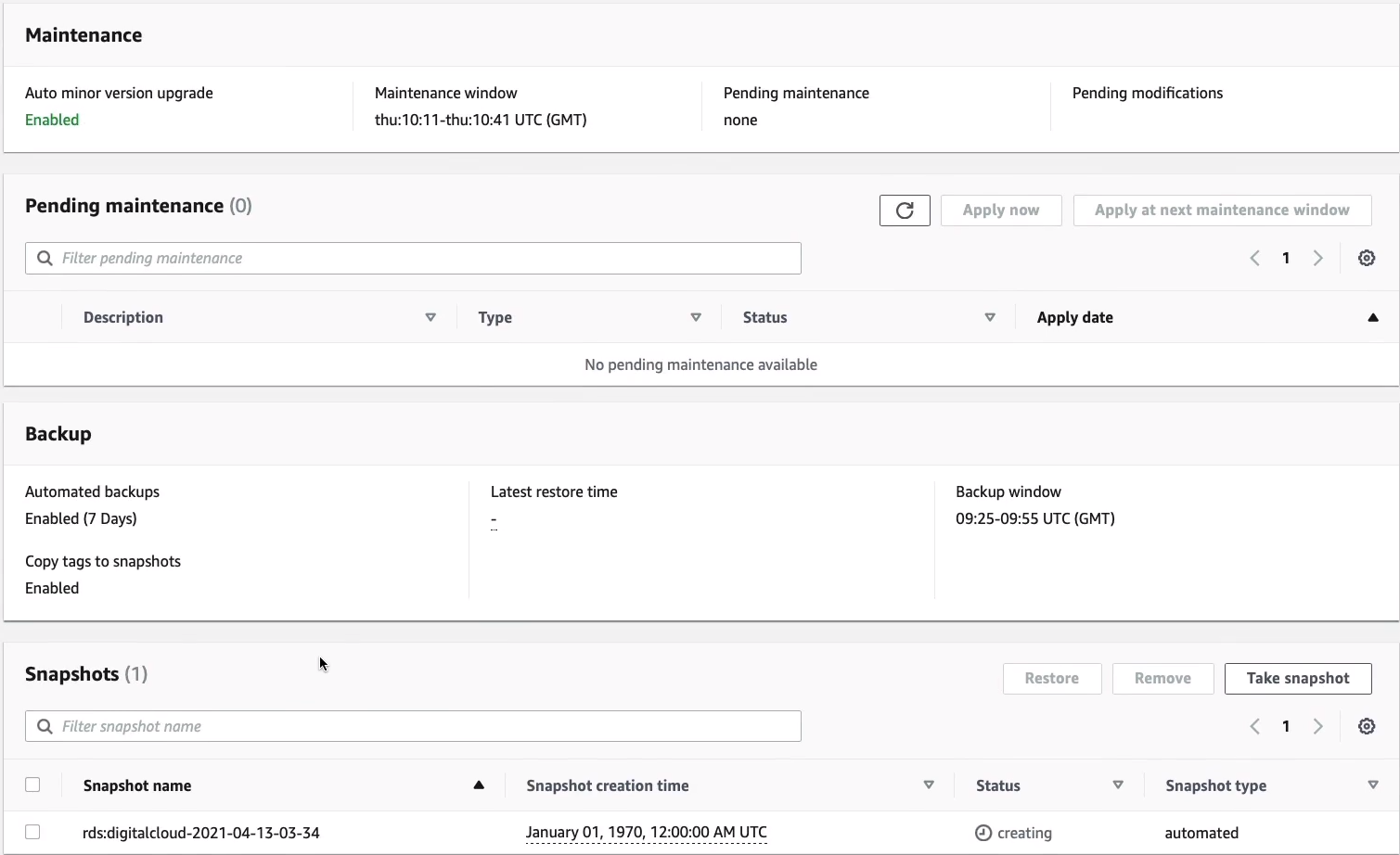
And under Maintenance & backups, you can see the configuration and any actual backups that have been taken.
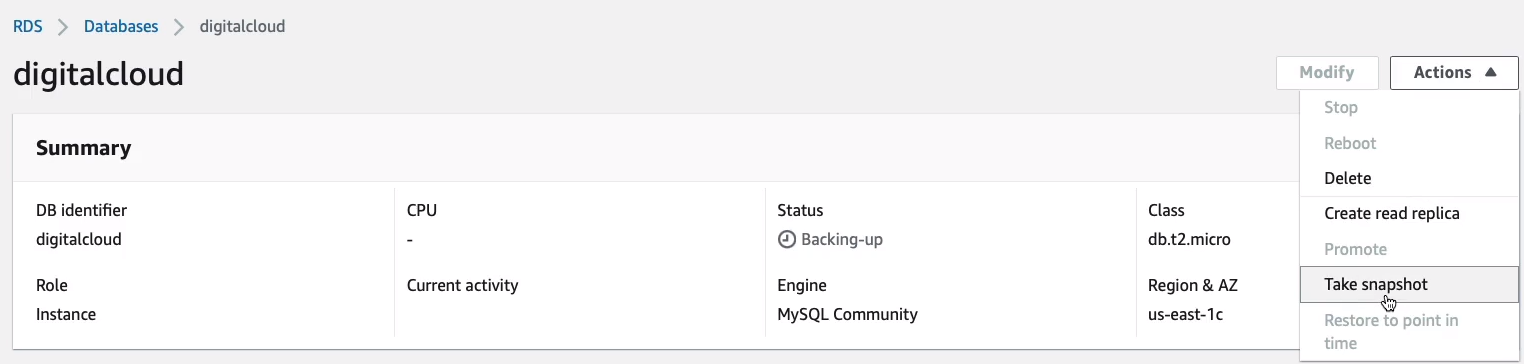
Back up at the top, you’ve got Actions. Here, you can do things like Take snapshot of your instance. Remember, it uses the Elastic Block Store. So you can always take snapshots and use those to restore your database, as well as the automatic backups that take place. You can Create read replica here and you can Promote a database instance that perhaps is a Read Replica to be a primary database. You can also, Delete, Reboot, and Stop your instance.
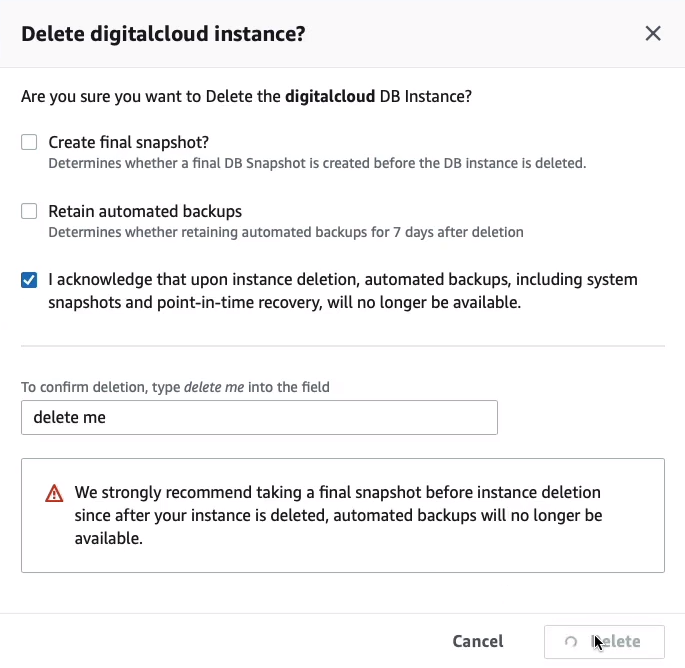
So all I’m going to do now is just go in and Delete my database.
And we don’t to create a final snapshot because we’ll have to pay to remain that. We don’t want to retain automated backups. So we just acknowledge that everything is going to get deleted. All we need to do is type delete me and then that’s it.
Amazon Aurora
Amazon Aurora is actually part of the RDS family. We could see it in the RDS Console, but it’s not called Amazon RDS. It’s just called Amazon Aurora and this is a proprietary database engine created by AWS.
- Amazon Aurora is an AWS database offering in the RDS family
- Amazon Aurora is a MySQL and PostgreSQL-compatible relational database built for the cloud
- Amazon Aurora is up to five times faster than standard MySQL databases and three times faster than standard PostgreSQL databases
- Amazon Aurora features a distributed, fault-tolerant, self-healing storage system that auto-scales up to 64TB per database instance
So here you can see that we have six different copies of our data, two in each availability zone. We have our Primary database with our Reads and Writes, and then we have our Replicas, which are in a different availability zone and each of them can perform reads but all writes go across this logical volume across multiple availability zones.
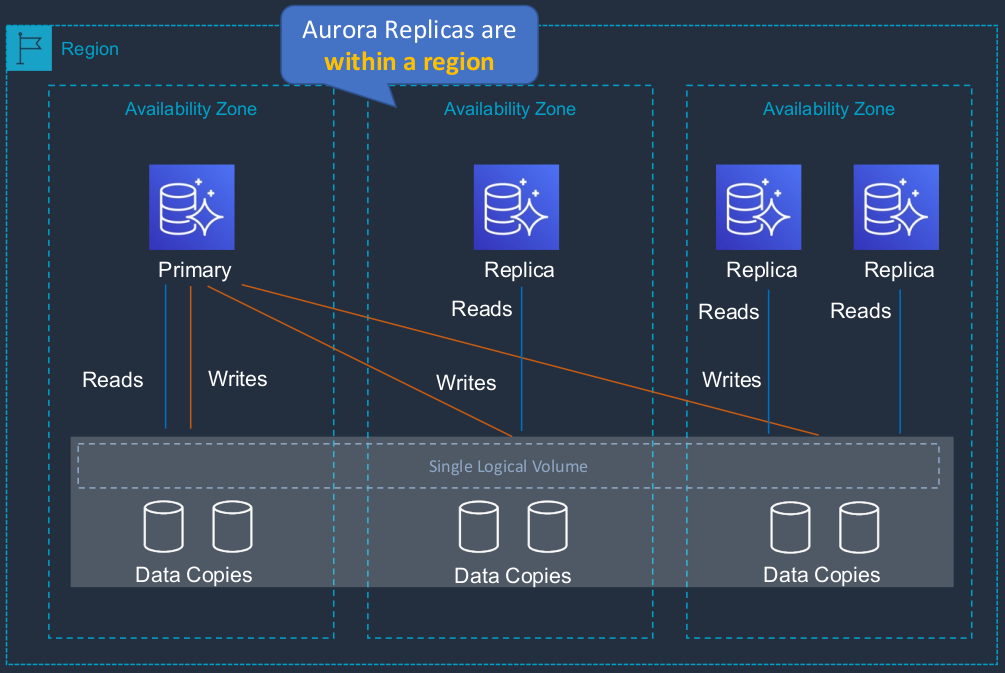
Aurora Fault Tolerance
- Fault tolerance across 3 Availability Zones
- Single logical volume
- Aurora Replicas scale-out read requests
- Can promote Aurora Replica to be a new primary or create a new primary
- Can use Auto Scaling to add replicas
- So that means that you can automatically have replicas instantiated when the database load goes a bit higher for query traffic.
Amazon Aurora Key Features
| Aurora Feature | Benefit |
|---|---|
| High performance and scalability | Offers high performance, self-healing storage that scales up to 64TB, point-in-time recovery, and continuous backup to S3 |
| DB compatibility | Compatible with existing MySQL and PostgreSQL open source databases |
| Aurora Replicas | In-region read scaling and failover target - up to 15 (can use Auto Scaling) |
| MySQL Read Replicas | Cross-region cluster with reading scaling and failover target - up to 5 (each can have up to 15 Aurora Replicas) |
| Global Database | Cross-region cluster with read scaling (fast replication / low latency reads). Can remove secondary and promote |
| Multi-Master | Scales out writes within a region - It basically means that you can have multiple database instances to which you can actually write data and it’s all synchronized between all of the different masters |
| Serverless | On-demand, autoscaling configuration for Amazon Aurora - does not support read replicas or public IPs (can only access through VPC or Direct Connect - not VPN) |
Amazon DynamoDB
- Fully managed NoSQL database service
- Key/value store and document store
- That means you can store document types of data or key values. So key value being you have the name, the key, and then the value which is the data
- It is a non-relational, key-value type of database
- Fully serverless service
- So it’s a completely serverless solution. You are not actually launching or paying for any instances. You just allocate certain characteristics of the performance to make sure that it’s going to provide adequate performance for your application and you pay according to that
- Push-button scaling
- It means that at any point in time, with a simple configuration change, you can increase or decrease the performance of your system without any interruption whatsoever.
Now, with RDS, you can change the configuration by changing the instance type but it does mean downtime. It does mean the instance is going to have to restart and your application won’t be able to connect to the database for a period of time. So DynamoDB does not have that problem. So we have a table in DynamoDB. It’s not a database because... it’s a database service, but the database is DynamoDB. You create multiple tables within an existing database. A DynamoDB table scales horizontally. Your data is being distributed across different backend servers to make sure that you can scale and that you get great performance.
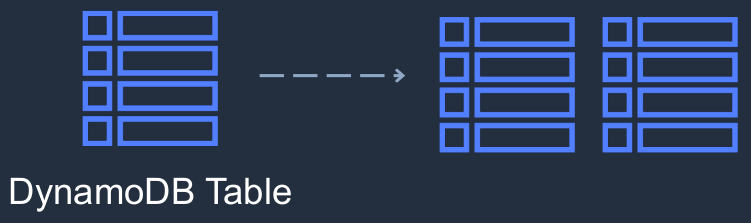
- DynamoDB is made up of:
- Tables
- That’s where all of your data is stored
- Items
- These are like rows in a relational database
- Attributes
- Each item has a series of attributes associated with it. So that’s the data we see in these different fields, such as the order ID, the book, the price, and the date.
- Tables

Amazon DynamoDB Key Features
| DynamoDB Feature | Benefit |
|---|---|
| Serverless | Fully managed, fault-tolerant, service - You don’t have any instances to manage or launch |
| Highly available | 99.99% availability SLA - 99.999% for Global Tables! |
| NoSQL type of database with Name / Value structure | Flexible schema, good for when data is not well structured or unpredictable |
| Horizontal scaling | Seamless scalability to any scale with push-button scaling or Auto Scaling |
| DynamoDB Accelerator (DAX) | Fully managed in-memory cache for DynamoDB that increases performance (microsecond latency) - An in-memory cache for really great performance |
| Backup | Point-in-time recovery down to the second in last 35 days; On-demand backup and restore |
| Global Tables | Fully managed multi-region, multi-master solution - So you can synchronize a database table across multiple regions and have the data constantly synchronize between the two |
Create Amazon DynamoDB Table
In the Console, go to Services > Database > DynamoDB. In DynamoDB we need to create a table. So let’s go to Tables and Create table.
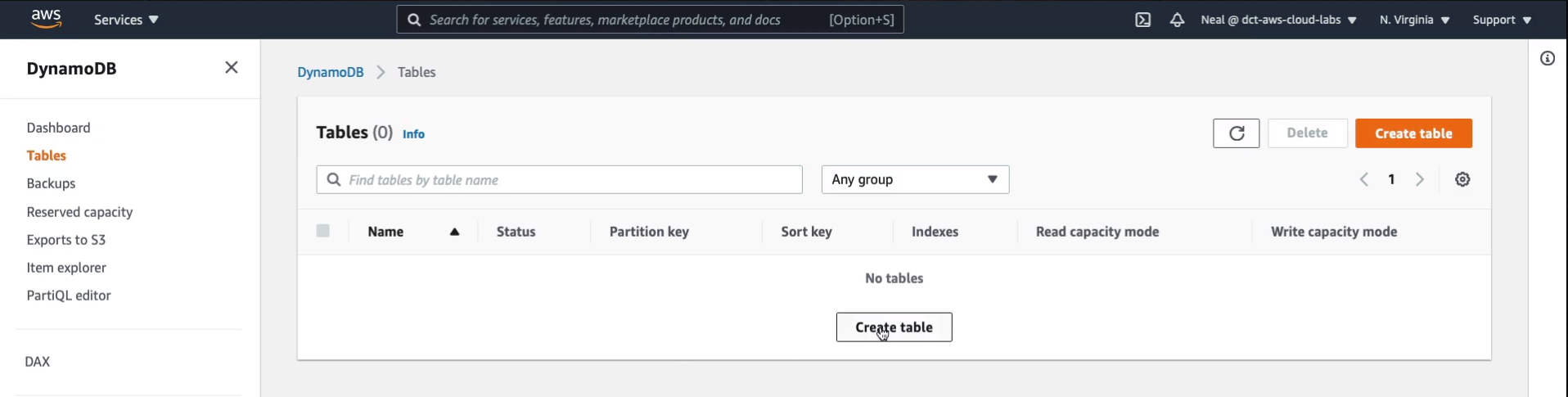
We need to give it a name. I’ll just simply call it MyTable and we need to give a Partition key. So what are we storing in this table? Maybe we’re storing some orders and associated with those orders, we’re going to have various information. Or maybe this table is going to be a series of users from a leader board for a gaming application and we’re going to store some information about those people. Let’s go with that one and we’ll just use userid for the partition key. Now, this can be a String, which is what we have here. It could be Binary or it could be a Number. So we’ll leave it as a string. You can then have a Sort Key that allows you to be able to search for another key that is related to the partition key. We’ll leave that blank, that is optional.
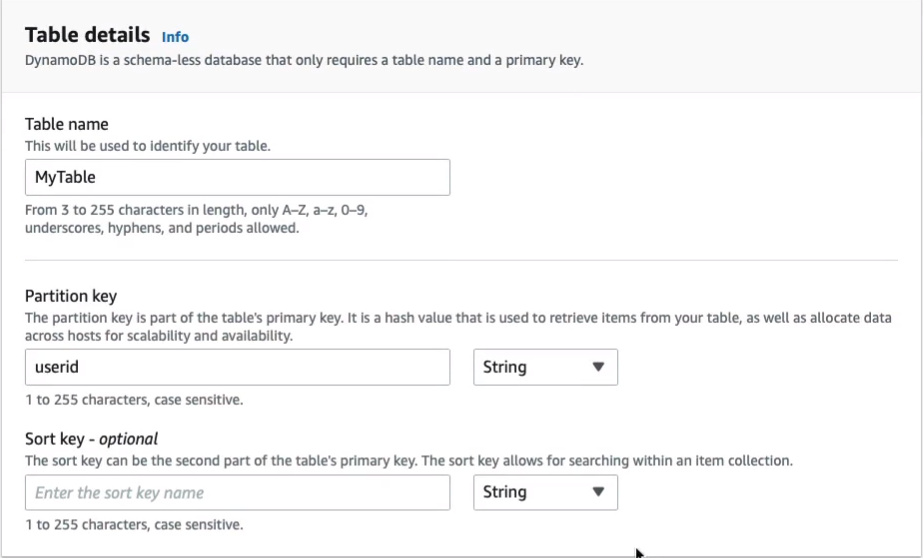
Now we have some Settings options here for Default settings or Customize settings. I’m going to click on Customize so I can show you a bit more. Now, we have something called Capacity mode. So here, we have On-demand or Provisioned. With Provisioned, we specify these things called Read capacity units and Write capacity units. And what this is, is it’s a way of actually defining the performance of your database. So you pay for read capacity units and write capacity units. Now, alternatively, you could go to On-demand and then you pay for the actual reads and writes that your application performs instead of provisioning them and just paying for five read capacity units and five write capacity units, regardless of whether you use them. Now, I’ll just leave it on the default hereof Provisioned. This is very low and it will be within the free tier.
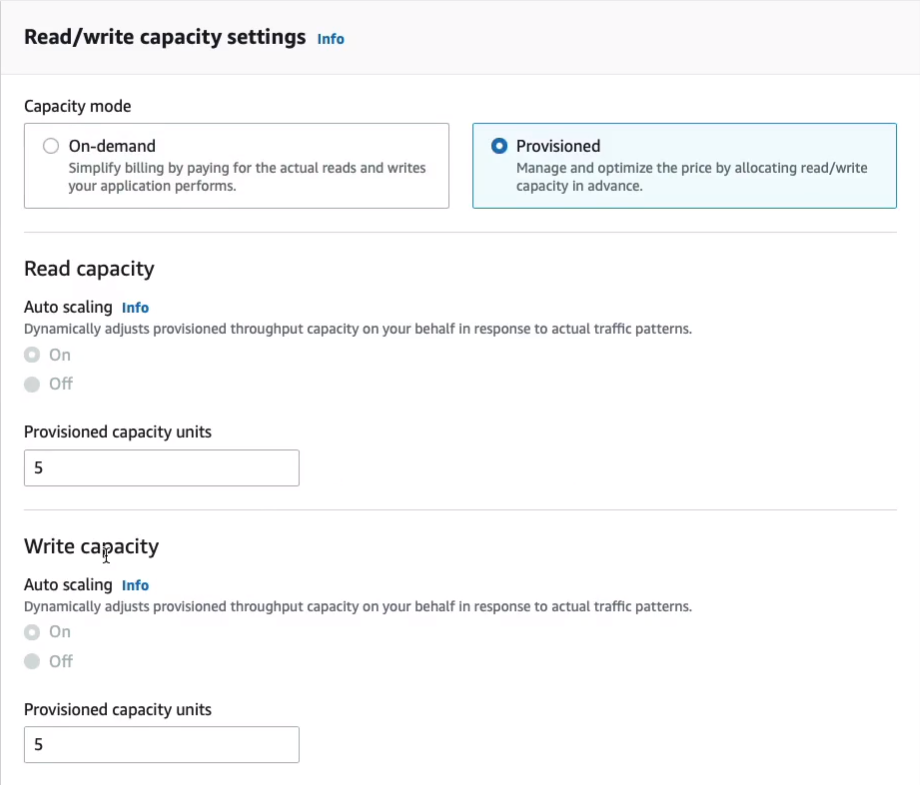
We can create something called a Secondary index beyond the scope of what we need to do here.
And so what I want to do now is just create the table. I’m not going to change the Encryption status. So let’s just click on Create table.
That’s it. That literally took a couple of seconds to create my table and we can see that it has a partition key of userid. So let’s just click on the MyTable.

So let’s just click on the table. Now, of course, there’s nothing on our table. We do not have any items on our table at this point. At the bottom here, we could actually Create item.
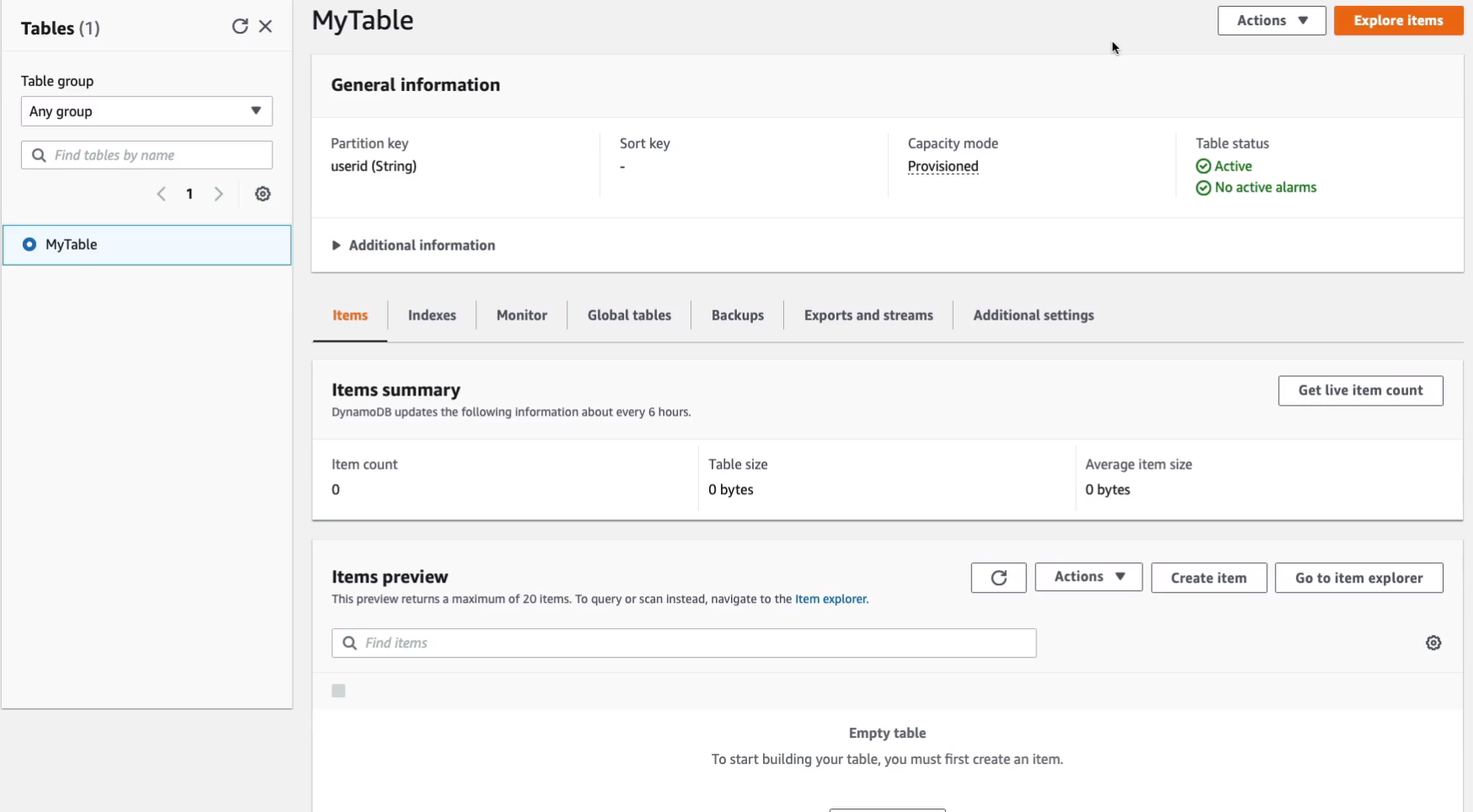
So let’s just go ahead and do that. So maybe this is going to be the first user and that’s going to be me. So the value for userid is neal001 and the type of that is going to be a string and we can’t change that. We could then add additional attributes. So maybe we need to add another string.
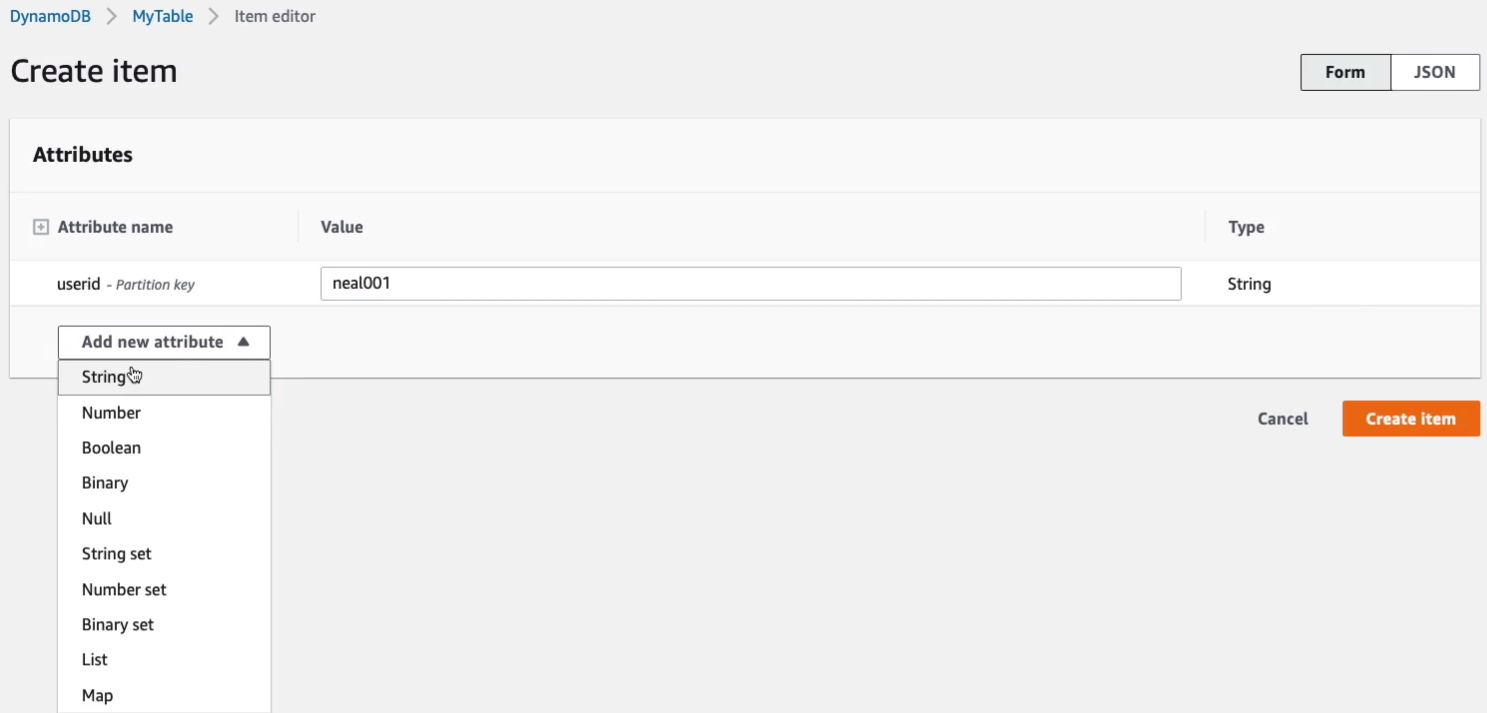
This one is going to be the firstname. So that would just be neal. We could have another one as a string and this might be lastname, davis, and then perhaps we have a number and that’s going to be bestscore and it’s 900. So let’s just create this item and see what happens.
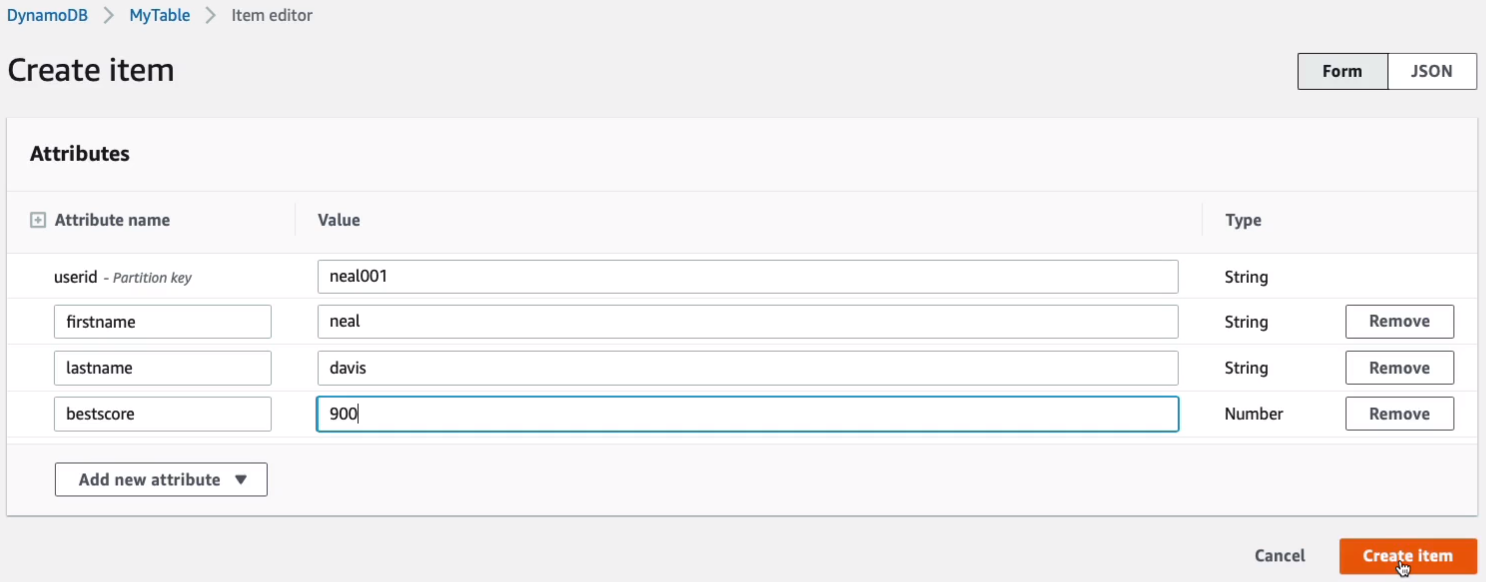
So now we have an item in our table which has a few different attributes associated with it. Now if we wanted to, we could go and just create more items and each item can have the same or different attributes and that’s one of the benefits of a NoSQL database because it gives you that flexibility. With a structured database like SQL, a relational database, you do actually have to make sure that you have some value in every single column. You can’t have different columns for different rows or items in the database. So that’s one of the advantages.

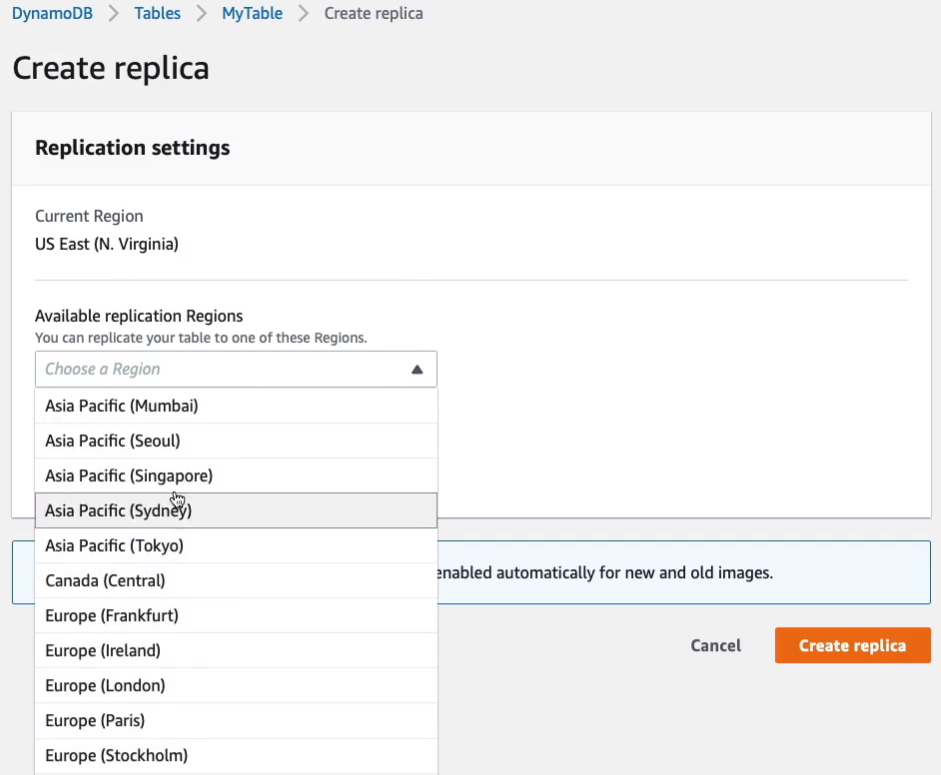
Now, there are a few tabs up here as well. We have something called Global Tables, a really cool solution where you can create a replica of your table and you can create that in another region.
So for example, I could then choose one of these other regions and have a replica created there for me.
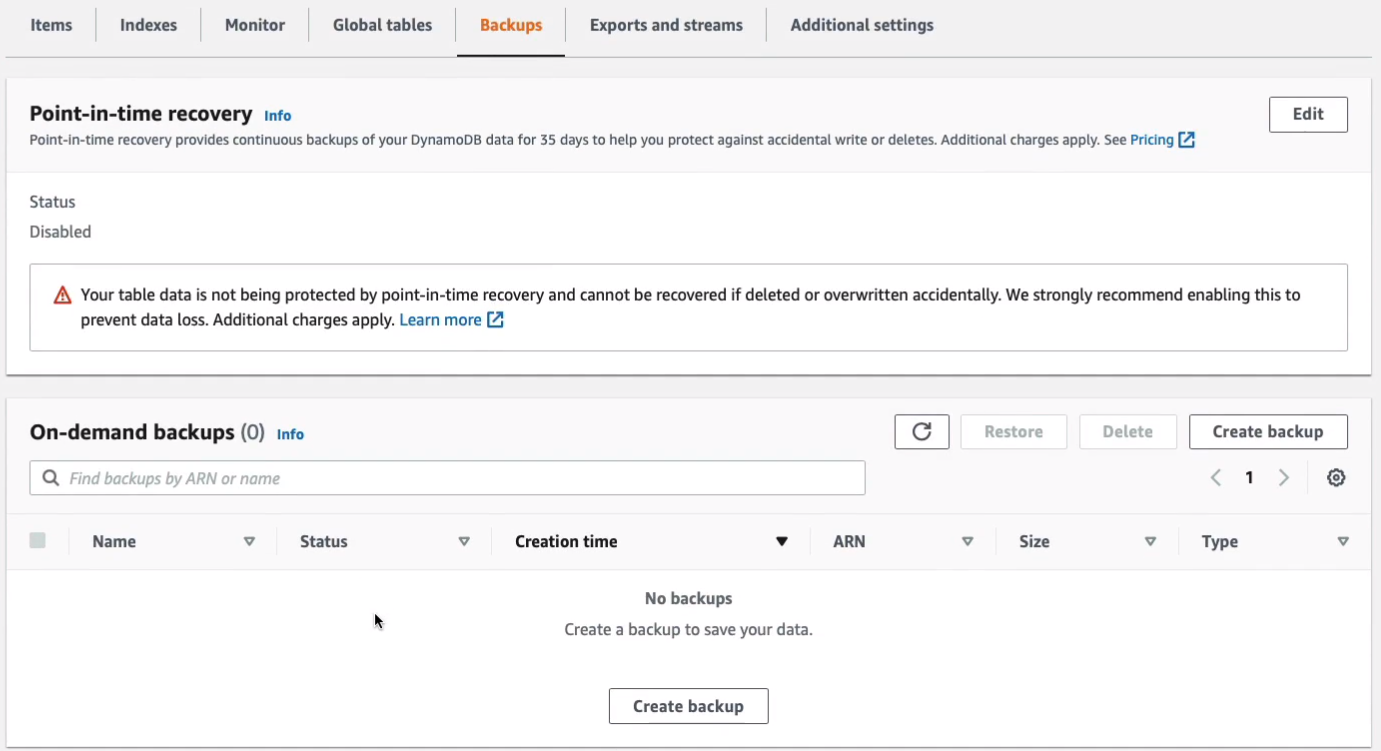
We can take backups, there’s an automated backup, and then you can also create on-demand backups as well.
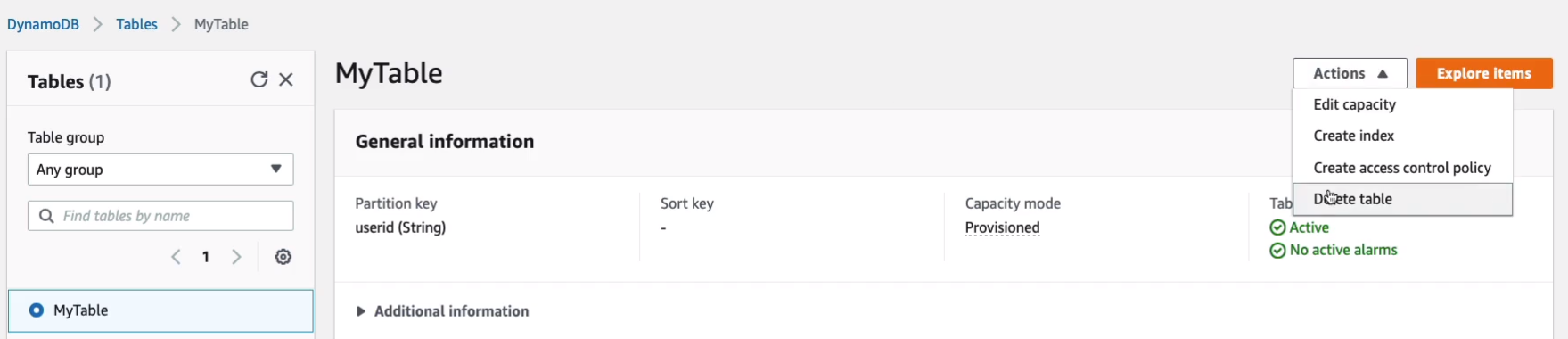
You really just need to understand that it’s a NoSQL type of database and that you have push-button scaling, so can scale it without any interruptions of traffic, and of course, it’s a serverless service, so you don’t have to provision instances or manage them. So that’s it, let’s just go and delete our table.
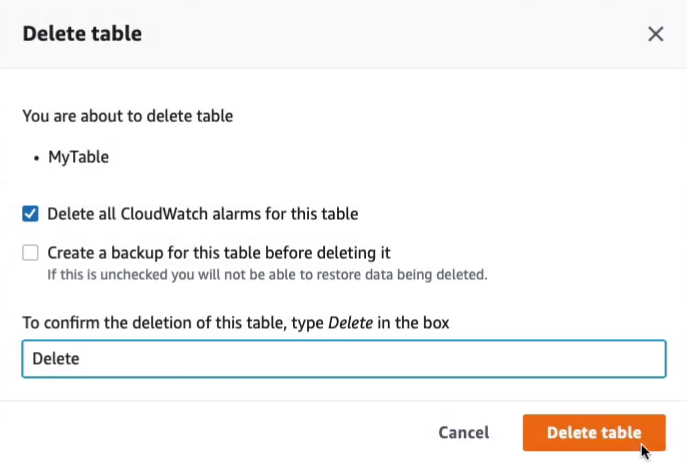
Once I type to Delete and Delete table, that’s it.
Amazon RedShift
So let’s say we have our Amazon RDS databases and these are our production databases. Perhaps these ones are somewhere in different geographies around the world and this is where we’re taking orders from our customers. So these are our transactional or OLTP databases. What we might want to do is actually load the data, copy it from those transactional databases into RedShift, which will become our data warehouse. So the data gets loaded into RedShift and then we can do stuff like analyzing the data with Business Intelligence tools such as QuickSight using Structured Query Language (SQL). So that should give you an idea of how we use databases such as RedShift, which is a data warehouse.
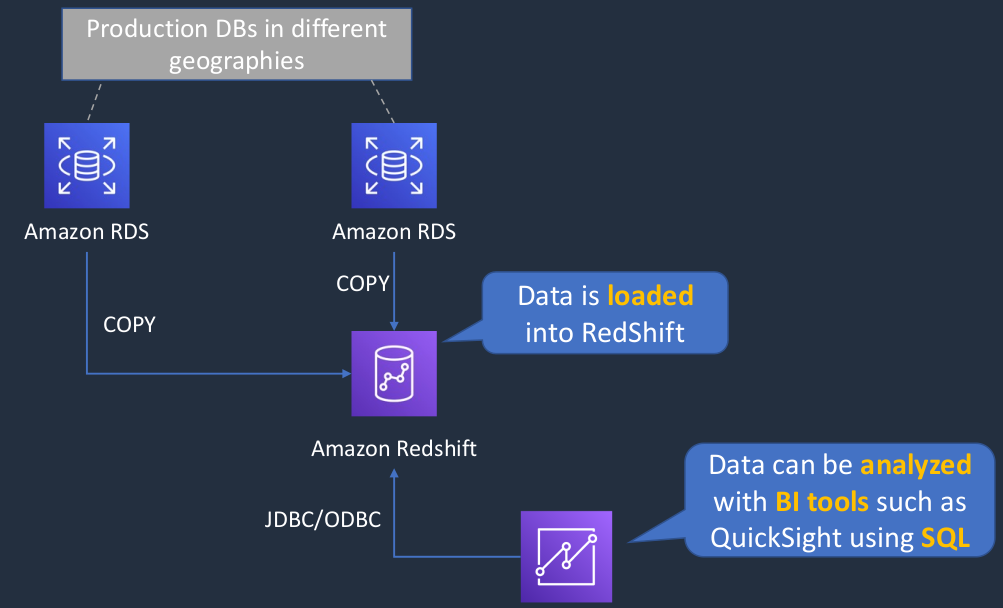
- Amazon RedShift is a fast, fully managed data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and existing Business Intelligence (BI) tools
- RedShift is a SQL based data warehouse used for analytics applications
- RedShift is a relational database that is used for Online Analytics Processing (OLAP) use cases
- RedShift uses Amazon EC2 instances, so you must choose an instance family/type
- RedShift always keeps three copies of your data
- RedShift provides continuous/incremental backups
Amazon Elastic Map Reduce (EMR)
You may have heard of Hadoop, which is a framework for big data. So big data, meaning you have large quantities of data and you need to perform some kind of analytics, some kind of processing on that data. Amazon Elastic Map Reduce (EMR), provides a managed implementation of Hadoop for you.
- Managed cluster platform that simplifies running big data frameworks including Apache Hadoop and Apache Spark
- Used for processing data for analytics and business intelligence
- Can also be used for transforming and moving large amounts of data
- Performs extract, transform, and load (ETL) functions
- Essentially it means you’re extracting data from one database solution. You need to transform it in some way so that you can then load it into perhaps a different type of database.
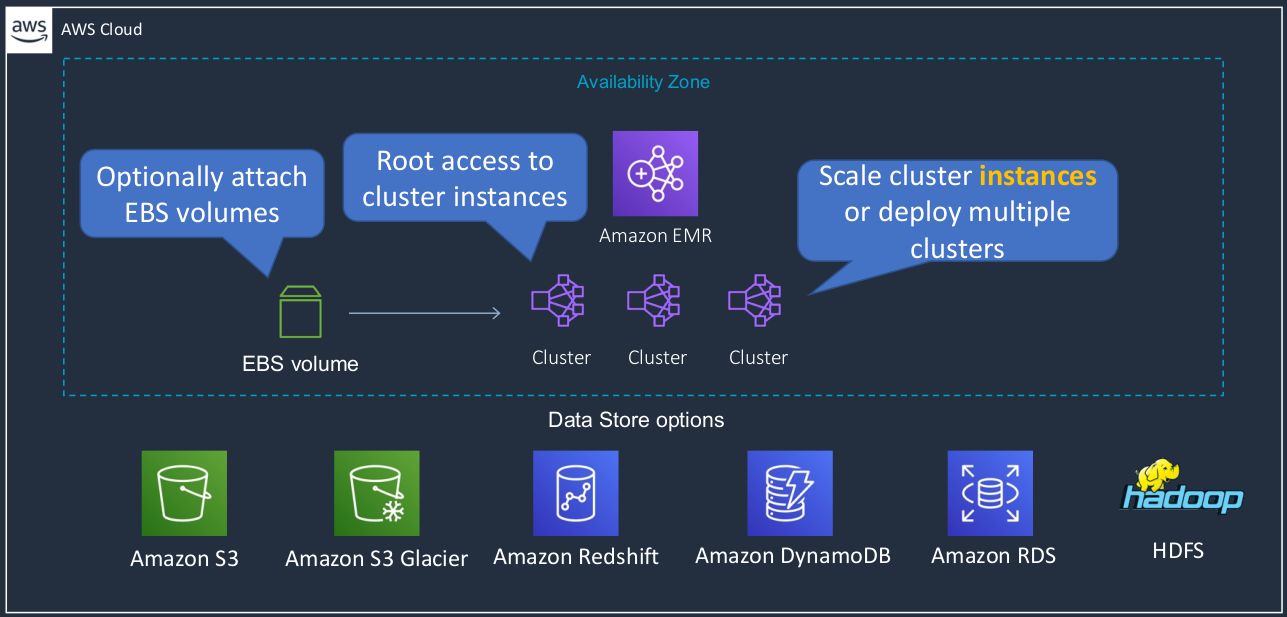
So we have an Availability Zone. An EMR always runs within an availability zone. It can then attach to various different data stores. So you can see we’ve got S3, we’ve got Glacier and RedShift and DynamoDB and RDS and Hadoop file system, HDFS as well. You can then also optionally have EBS volumes and then you have your cluster instances and you get root access to your cluster instances in EMR. EMR scales by adding cluster instances or deploying multiple clusters and you can do that then in different availability zones if you like. The key things to remember are that it’s a managed implementation of Hadoop and it’s used for big data analytics and business intelligence.
Amazon ElastiCache
Amazon ElastiCache is a database service that’s typically used for very high performance in-memory caching of data and often that data comes from another database such as RDS.
- Fully managed implementations Redis and Memcached
- ElastiCache is a key/value store
- So it stores data in a key-value format
- In-memory database offering high performance and low latency
- Can be put in front of databases such as RDS and DynamoDB
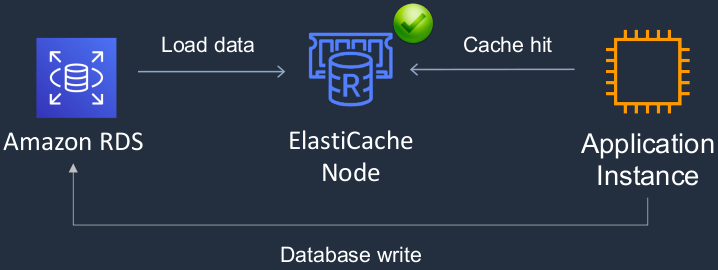
We have an RDS database and we have an application instance and what we do is we put an ElastiCache node in the middle. Now, the nodes actually run on EC2 instances. So again, you have to launch EC2 instances here and actually pay for those instances for the time you’re running them. Now, the application is going to write some data to RDS. That data then gets loaded into ElastiCache, which means that the next time the application needs to read the data from the database, it gets what’s called a Cache hit, which means it found it in the database and it’s going to be retrieved a lot faster than coming from RDS.
- ElastiCache nodes run on Amazon EC2 instances, so you must choose an instance family/type
| Use case | Benefit |
|---|---|
| Web session store | In cases with load-balanced web servers, store web session information in Redis so if a server is lost, the session info is not lost, and another webserver can pick it up - So you’re storing state information in this particular database, which can be retrieved by instances. Perhaps you have some load-balanced Web servers and they’re storing some information about a customer session in ElastiCache and then if one of the Web servers fails and the connection gets routed over to another instance, that instance can find the information in ElastiCache. And obviously, it’s very high performance so it’s good for those types of use cases. |
| Database caching | Use Memcached in front of AWS RDS to cache popular queries to offload work from RDS and return results faster to users |
| Leaderboards | Use Redis to provide a live leaderboard for millions of users of your mobile app |
| Streaming data dashboards | Provide a landing spot for streaming sensor data on the factory floor, providing live real-time dashboard displays |
The key thing to remember it is an in-memory database used for caching data.
Amazon Athena and AWS Glue
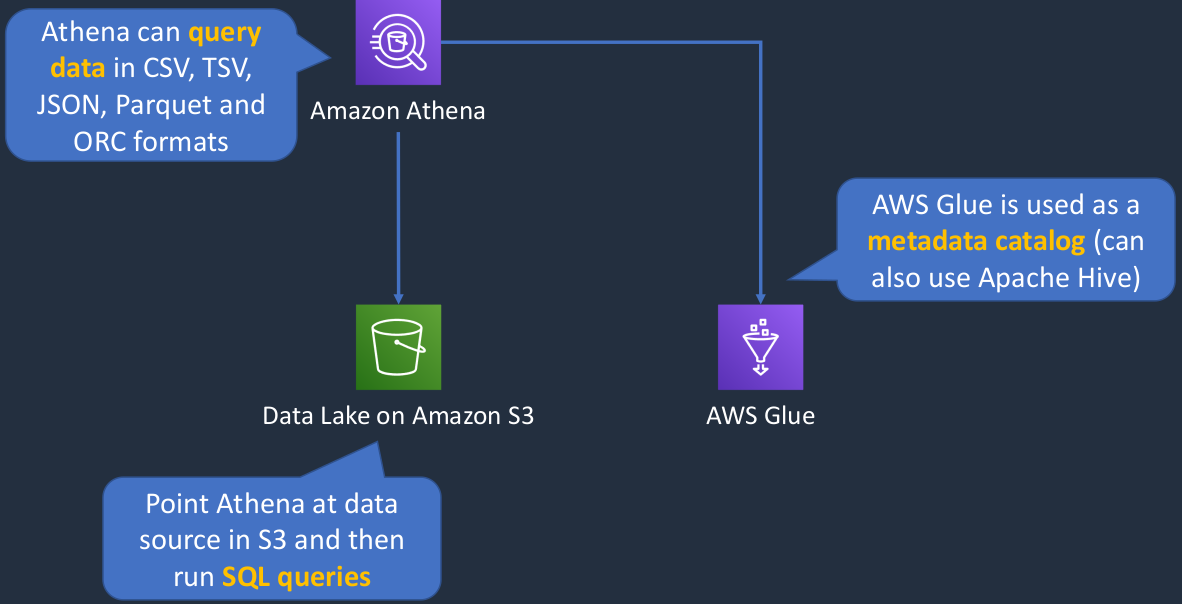
So Amazon Athena is a service that we can point at data on Amazon S3 and we’re able to run SQL queries against that data. So it gives us that ability to take a data lake, which means essentially you have a large quantity of data on S3, and you’re able to run queries to find out some information as if it was a database. Athena can query data that’s in various different formats. So it might be stored in a CSV file, a TSV file, in JSON format, in Parquet or ORC formats as well. We then have AWS Glue. Now, Glue is a metadata catalog that you can use with Amazon Athena. So in this case, you can create a metadata catalog that describes your data structure in S3 and then query using SQL to that data in S3.
Amazon Athena
- Athena queries data in S3 using SQL
- Can be connected to other data sources with Lambda
- Data can be in CSV, TSV, JSON, Parquet, and ORC formats
- Uses a managed Data Catalog (AWS Glue) to store information and schemas about the databases and tables
AWS Glue
- Fully managed extract, transform and load (ETL) service
- Used for preparing data for analytics
- AWS Glue runs the ETL jobs on a fully managed, scale-out Apache Spark environment
- Works with data lakes (e.g. data on S3), data warehouses (including RedShfit), and data stores (including RDS or EC2 databases)
Amazon Kinesis
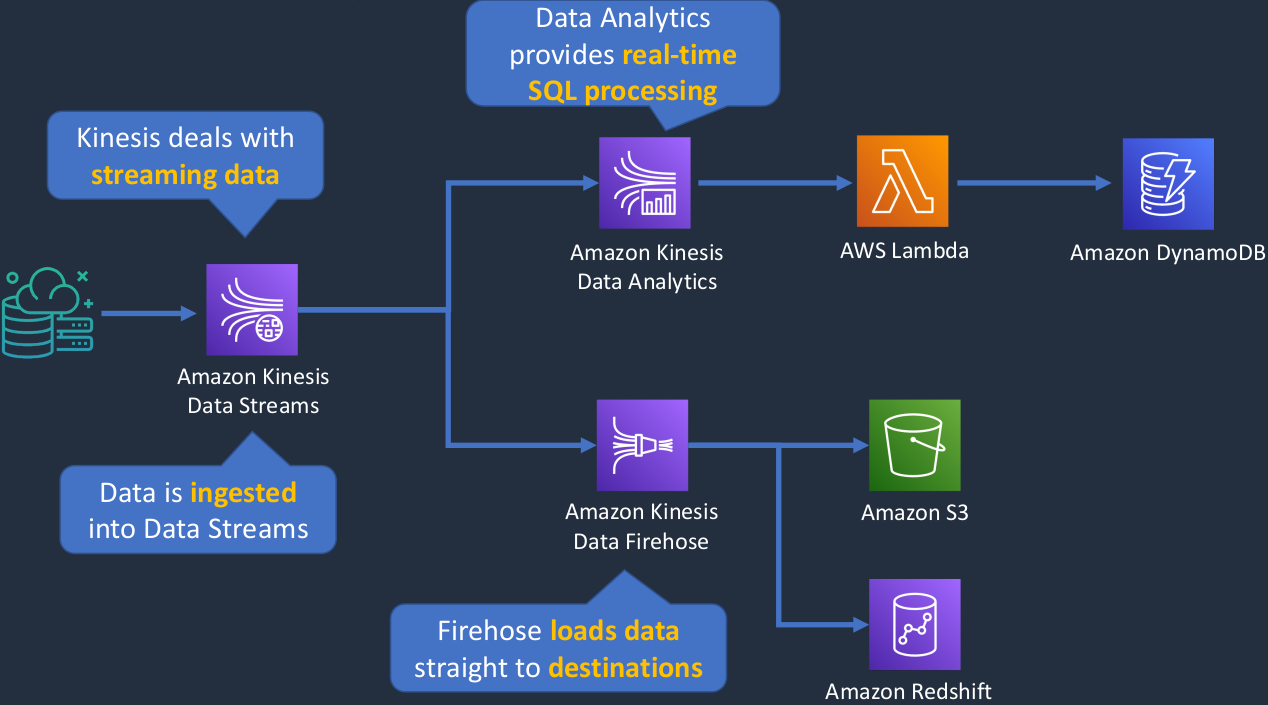
Amazon Kinesis is a service that’s made up of multiple different services but they’re all associated with streaming data. That’s the main thing I want you to remember is to think about Kinesis whenever you hear about streaming data. So we have our data coming in from some kind of source. These could be things like IoT sensors or some kind of device on the Internet or in a factory and they’re sending data in and that's hitting Kinesis data streams. So that’s one of the products in the portfolio. Kinesis data streams deal with streaming data. It ingests that data and then it can do something with it, so it can then process that data and forward it on. And in this case, maybe it’s forwarding on to another member of the Kinesis family, which is the Kinesis Data Analytics Service. Data Analytics will perform real-time SQL processing on data and then perhaps it’s going to send it through to Lambda and Lambda might store in a DynamoDB table and then we have Kinesis Data Firehose. Firehose is a service that loads data straight to a destination. So in other words, it might just put the data into S3 or it might put it into Amazon RedShift and then you’ll be able to do something with that data later on. So it’s just a way of taking that streaming data as it comes in and says, “Right, I’m just going to dump it all into Amazon S3 or load it into a RedShift database and then I can perform my queries on it later on.”
Examples of streaming data use cases include:
- Purchases from online stores
- Stock prices
- Game data (statistics and results as the gamer plays)
- Social network data
- Geospatial data (think uber.com)
- IoT sensor data
So we’re really talking about data that comes in often in fairly large and fairly consistent volumes. So it might be data that’s constantly being sent by a sensor recording information about some equipment or about the temperature or about the movement of a car, for example. So it’s giving back some coordinates. There are lots of different use cases here, and it’s really just about dealing with this constant stream of data that’s coming in.
Kinesis Data Streams
- Producers send data that is stored in shards for up to 7 days
- Consumers process the data and save it to another service
Amazon Kinesis Data Firehose
- No shards, completely automated and elastically scalable
- Saves data directly to another service such as S3, Splunk, RedShift or Elasticsearch
Amazon Kinesis Data Analytics
- Provides real-time SQL processing for streaming data
Other Databases and Analytics Services
AWS Data Pipeline
- Processes and moves data between different AWS compute and storage services
- Save results to services including S3, RDS, DynamoDB, and EMR
Amazon QuickSight
- Business intelligence (BI) service
- Create and publish interactive BI dashboards for Machine Learning-powered insights
Amazon Neptune
- Fully managed graph database service
Amazon DocumentDB
- Fully managed document database service (non-relational)
- Supports MongoDB workloads
- Queries and indexes JSON data
Amazon QLDB
- Fully managed ledger database for immutable change history
- Provides cryptographically verifiable transaction logging
- Essentially it provides a ledger, a recording of exactly what transactions have taken place in a way that’s very difficult to sort of manipulate in any way.
Amazon Managed Blockchain
- Fully managed service for joining public and private networks using Hyperledger Fabric and Ethereum
Exam-Cram
Amazon Relational Database Service (RD)
- RDS uses EC2 instances, so you must choose an instance family/type
- Relational databases are known as Structured Query Language (SQL) databases
- RDS is an Online Transaction Processing (OLTP) type of database
- Easy to set up, highly available, fault-tolerant, and scalable
- Common use cases include online stores and banking systems
- Can encrypt your Amazon RDS instances and snapshots at rest
- Encryption uses AWS Key Management Service (KMS)
- Amazon RDS supports the following database engines:
- SQL Server, Oracle, MySQL Server, PostgreSQL, Aurora, MariaDB
- Scales up by increasing instance size (compute and storage)
- Read replicas option for read-heavy workloads (scales out for reads/queries only)
- Disaster recovery with Multi-AZ option
Amazon Aurora
- Amazon Aurora is an AWS database offering in the RDS family
- Amazon Aurora is a MySQL and PostgreSQL-compatible relational database built for the cloud
- Amazon Aurora features a distributed, fault-tolerant, self-healing storage system that auto-scales up to 128TB per database instance
Amazon DynamoDB
- Fully managed NoSQL database service
- Key/value store and document store
- It is a non-relational, key-value type of database
- Fully serverless service
- Push-button scaling
Amazon RedShift
- RedShift is a SQL based data warehouse used for analytics applications
- RedShift is a relational database that is used for Online Analytics Processing (OLAP) use cases
- RedShift uses Amazon EC2 instances, so you must choose an instance family/type
- RedShift always keeps three copies of your data
- RedShift provides continuous/incremental backups
Amazon EMR
- Managed cluster platform that simplifies running big data frameworks including Apache Hadoop and Apache Spark
- Used for processing data for analytics and business intelligence
- Can also be used for transforming and moving large amounts of data
- Performs extract, transform, and load (ETL) functions
Amazon ElastiCache
- Fully managed implementations Redis and Memcache
- ElastiCache is a key/value store
- In-memory database offering high performance and low latency
- Can be put in front of databases such as RDS and DynamoDB
Amazon Athena
- Athena queries data in S3 using SQL
- Can be connected to other data sources with Lambda
- Data can be in CSV, TSV, JSON, Parquet, and ORC formats
- Uses a managed Data Catalog (AWS Glue) to store information and schemas about the databases and tables
AWS Glue
- Fully managed extract, transform, and load (ETL) service
- Used for preparing data for analytics
- AWS Glue runs the ETL jobs on a fully managed, scale-out Apache Spark environment
- Works with data lakes (e.g. data on S3), data warehouses (including RedShift), and data stores (including RDS or EC2 instances)
Amazon Kinesis Data Streams
- Producers send data that is stored in shards for up to 7 days
- Consumers process the data and save it to another service
Amazon Kinesis Data Firehose
- No shards, completely automated and elastically scalable
- Saves data directly to another service such as S3, Splunk, RedShift, or Elasticsearch
Amazon Kinesis Data Analytics
- Provides real-time SQL processing for streaming data
AWS Data Pipeline
- Processes and moves data between different AWS compute and storage services
- Save results to services including S3, RDS, DynamoDB, and EMR
Amazon QuickSight
- Business intelligence (BI) service
- Create and public interactive BI dashboards for Machine Learning-powered insights
Amazon Neptune
- Fully managed graph database service
Amazon DocumentDB
- Fully managed document database service (non-relational)
- Supports MongoDB workloads
- Queries and indexes JSON data
Amazon QLDB
- Fully managed ledger database for immutable change history
- Provides cryptographically verifiable transaction logging
Amazon Managed Blockchain
- Fully managed service for joining public and private networks using Hyperledger Fabric and Ethereum